Goal
3D hand pose estimation from a single color image with a learning based formulation.
Background
- Use of multiple cameras limits the application domain
- Depth cameras are not as commonly available and only work reliably in indoor environments
Representation
- 21 joints in 3D space
- Normalize the distance between certain pair of key-points to unit length (to solve scale ambiguity)
- Translation invariant representation by subtracting location of defined root key-point
Estimation
consist of three deep networks.
- First network (HandSegNet) : hand segmentation
- Second network (PoseNet) : hand keypoints localization
- Third network (PosePrior) : 3d hand pose derivation
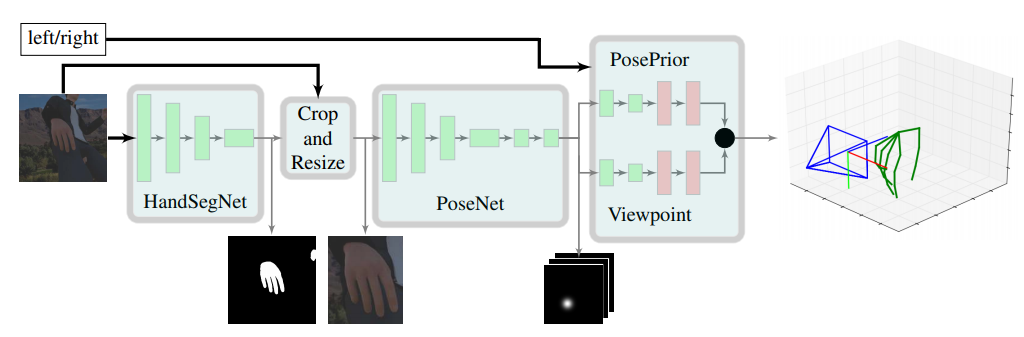
HandSegNet
- CNN based on Convolutional Pose Machines
- create hand mask
- simplifies the learning task for the PoseNet
- crop and normalize the inputs in size
PoseNet
- CNN based on Convolutional Pose Machines
- predict joints score maps that contains likelihood that a certain keypoint is present at a spatial location
- produce image feature representation
- predict initial score map and successively refine in resolution
PosePrior Network
- predict relative and normalized 3D coordinates on incomplete/noisy score maps
- learn possible hand articulations and prior probabilities

- combine two predictions to estimate relative normalized coordinates
- estimate canonical coordinates from canonical frame Wc
- estimate viewpoint from rotation matrix R
Dataset
two available datasets to apply
- Stereo Hand Pose Tracking Benchmark
- 18000 stereo pairs
- 2D and 3D annotations of 21 keypoints
- 640 x 480 resolution
- Dexter
- 3129 color images, depth maps
- annotations for fingertips and cuboid corners
- 640 x 320 resolution
these are not sufficient because of,
- limited variation
- partially incomplete annotation
To avoid known problem of poor labeling performance by human annotators in 3D data,
complement stereo and dexter dataset with,
- Mixamo : 3D models of humans with corresponding animations
- Blender : open source software to render images

total 41258 training images and 2728 evaluation images with,
- 21 key-points per hand : four of each finger (4x5), root(1)
- 33 classes segmentation mask : three of each finger (3x10), palm (2), person (1)
- 320 x 320 resolution
- random location in spherical vicinity around hand
- random background from 1231 images
- random lighting (directional light and global illumination)
- random light positions and intensities
- random JPG compression quality (0~60%)
- random specular reflection effect on the skin
Experiment
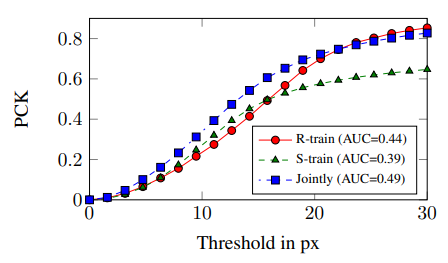

*PCK : Percentage of Correct Keypoints
Conclusion

- first learning based system to estimate 3d hand pose from a single image
- contributed large synthetic dataset
- performance mostly limited by lack of annotated large scale dataset with real world images and diverse pose statistics