Goal
Track hand pose from unconstrained monocular RGB video streams at real-time framerates
Background
Multi-view methods
- Hard to setup (calibration)
- Hard to operate on general hand motions in unconstrained scenes
- Expensive
Monocular methods
- Without setup overhead
- Do not work in all scenes (e.g. outdoor with sunlight)
- Higher power consumption
- Not robust to occlusions by objects
- Not able to distinguish 3D poses with the same 2D joint position projection
Learning-based methods
- Difficult to obtain annotated data with sufficient real-world variations
- Suffer from occlusions due to objects being manipulated by the hand
- Synthetic data has a domain gap when models trained on this data are applied to real input
- Hard to obtain real-synthetic image pairs
Dataset
Since the annotation of 3D joint positions in hundreds of real hand images is infeasible, synthetically generated images are commonly used.
Real hand image
28,903 Real hand image with desktop webcam
Synthetic hand image
SynthHands dataset from state-of-the-art datasets
- Real-time hand tracking under occlusion from an egocentric RGB-D sensor
- Learning to Estimate 3D Hand Pose from Single RGB Images
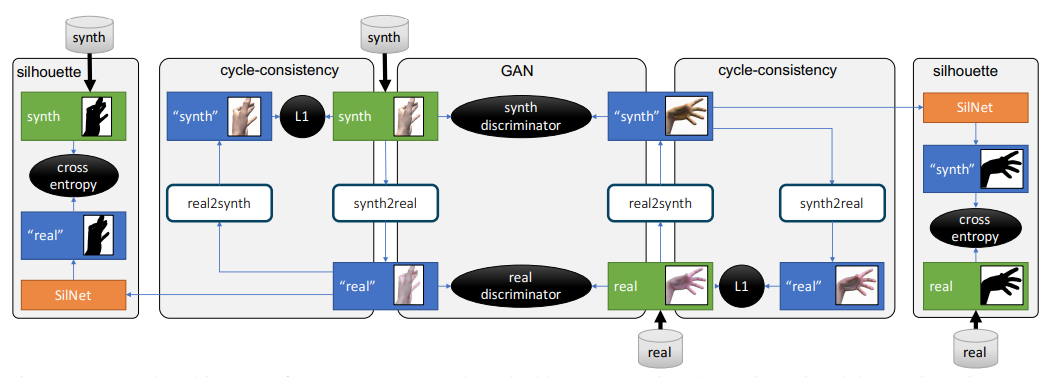
GeoConGAN
Translate synthetic to real images based on CycleGAN
- Uses adversarial discriminators to learn cycle-consistent forward and backward mappings
- Has two trainable translators synth2real and real2synth
- Does not require paired images
- Preserve poses during translation
Extract the silhouettes of the images by training a binary classification network, SilNet based on simple UNet.
- Has three 2-strided convolutions and three deconvolutions
Data Augmentation
- Composite GANerated images with random background images
- Randomly textured object by leveraging the object masks
Hand Joints Regression
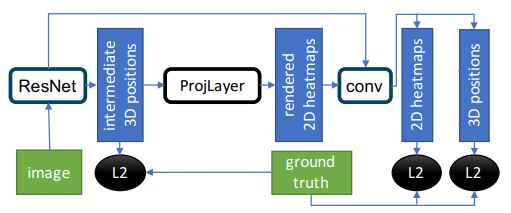
Train a CNN, the RegNet derived from the ResNet50, that predicts 2D and 3D positions of 21 hand joints with about 440,000 samples (60% GANerated)
- 2D joint positions are represented as heatmaps in image space : represent uncertainities
- 3D positions are represented as 3D coordinates relative to the root joint : resolve the depth ambiguities
- Additional refinement module based on projection layer (ProjLayer) to better coalesce 2D & 3D predictions
Kinematic Skeleton Fitting
Kinematic Hand Model
Comprises one root joint and 20 finger joints.
- Per-user skeleton adaptation : obtain averaging relative bone lengths of 2D prediction over 30 frames while the users hold their hand parallel to the camera image plane
2D Fitting Term
Minimize the distance between the hand point position projected onto the image plane and the heatmap maxima.
3D Fitting Term
- Obtain a good hand articulation by using the predicted relative 3D joint positions
- Resolve depth ambiguities that are present when using 2D joint positions only
Joint Angle Constraints
Penalize anatomically implausible hand articulations by enforcing that joints do not bend too far
Temporal Smoothness
Penalize deviations from constant velocity
Optimization
- Minimize the energy in gradient-descent strategy,
- Use that the root joint and four direct children joints (respective non-thumb MCP joints) are rigid
Experiments
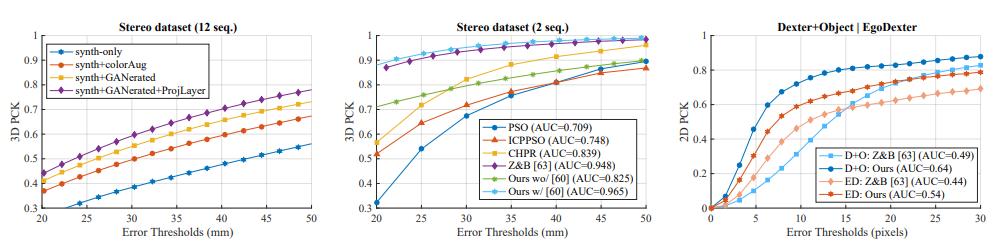
Use the Percentage of Correct Keypoints (PCK) score that is a popular criterion to evaluate pose estimation accuracy
Conclusion
Real-time hand tracking system with,

- Monocular RGB-only image without multi-view or depth image
- Synthetic generation of training data based on geometrically consistent image-to-image translation network (GeoConGAN)
- Training convolutional neural network (RegNet)
- Kinematic skeleton fitting
Outperforms,
- Without setup overhead
- Lower power consumption
- From unconstrained images (does not require paired images)
- Preserve poses during translation
- Robust to occlusions and varying camera viewpoints
- More precise than state-of-the-art methods
Reference
https://handtracker.mpi-inf.mpg.de/projects/GANeratedHands/content/GANeratedHands_CVPR2018.pdf